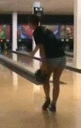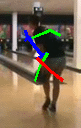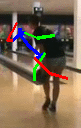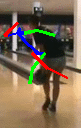Forecasting Human Dynamics from Static Images
Abstract
This paper presents the first study on forecasting human dynamics from static images. The problem is to input a single RGB image and generate a sequence of upcoming human body poses in 3D. To address the problem, we propose the 3D Pose Forecasting Network (3D-PFNet). Our 3D-PFNet integrates recent advances on single-image human pose estimation and sequence prediction, and converts the 2D predictions into 3D space. We train our 3D-PFNet using a three-step training strategy to leverage a diverse source of training data, including image and video based human pose datasets and 3D motion capture (MoCap) data. We demonstrate competitive performance of our 3D-PFNet on 2D pose forecasting and 3D structure recovery through quantitative and qualitative results.
Forecasting 2D Poses
Below are some selected animations showing the forecasted 2D poses generated by our model. Note that the action labels are not used in obtaining the results, but are shown here just for the visualization purpose.
Recovering 3D Pose and Rendering Human Character
Our model also converts the forecasted 2D skeletal poses into 3D space. For better interpreteration, we render human characters from the output 3D skeletal poses using the public code provided by Chen et al. [1].
| Forecasted 2D Pose |
|
Forecasted 3D Pose |
|
Rendered Human Character |
|
Ground-truth
Frame & Pose |
| Forecasted 2D Pose |
|
Forecasted 3D Pose |
|
Rendered Human Character |
|
Ground-truth
Frame & Pose |
| Forecasted 2D Pose |
|
Forecasted 3D Pose |
|
Rendered Human Character |
|
Ground-truth
Frame & Pose |
| Forecasted 2D Pose |
|
Forecasted 3D Pose |
|
Rendered Human Character |
|
Ground-truth
Frame & Pose |
| Forecasted 2D Pose |
|
Forecasted 3D Pose |
|
Rendered Human Character |
|
Ground-truth
Frame & Pose |
| Forecasted 2D Pose |
|
Forecasted 3D Pose |
|
Rendered Human Character |
|
Ground-truth
Frame & Pose |
| Forecasted 2D Pose |
|
Forecasted 3D Pose |
|
Rendered Human Character |
|
Ground-truth
Frame & Pose |
| Forecasted 2D Pose |
|
Forecasted 3D Pose |
|
Rendered Human Character |
|
Ground-truth
Frame & Pose |
Paper
Forecasting Human Dynamics from Static Images.
Yu-Wei Chao, Jimei Yang, Brian Price, Scott Cohen, and Jia Deng.
IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2017.
[paper]
[supplementary material]
[arXiv]
[poster]
[bibtex]
Code
The source code is publicly available on GitHub, and distributed in three self-contained repos.
image-play
The main repo with code for training and evaluating the full network. This also provides the full source code by including the other two repos.
skeleton2d3d
Source code for just training and evaluating the 3D skeleton converter.
References
- W. Chen, H. Wang, Y. Li, H. Su, Z. Wang, C. Tu, D. Lischinski, D. Cohen-Or, and B. Chen. Synthesizing training images for boosting human 3d pose estimation. In 3DV, 2016.
Contact
Send any comments or questions to Yu-Wei Chao: ywchao@umich.edu.
Last updated on 2018/07/19